How the Anselm Project Generates Biblical Studies
Explore how the Anselm Project generates biblical studies reports using a mixture-of-experts AI pipeline, validated references, and structured JSON outputs.
I get asked occasionally how the Anselm Project actually works under the hood. Fair question. Here's the technical process behind every biblical report you generate.
The First Engine
This was the first serious engine I built for the Anselm Project, and it's still running today because the product is good. I've refined it over time, but the core pipeline remains the same.
The Six-Step Process
1. Reference Validation
Before anything happens, the system validates your Bible reference. I wrote strict rules into the validator:
- Accepts formats like "John 3:16", "John 3:16-18", or "John 3-4"
- Standardizes everything to use colons and hyphens consistently
- Enforces specific limits (chapter ranges must be exactly two consecutive chapters)
- Validates against actual book chapter counts to prevent nonsense
If you type "John 3.16" or "Jn 3:16" the system standardizes it to "John 3:16" before processing.
2. Text Retrieval
The system pulls the full translated text from the Anselm Project Bible (APB) from my compiled JSON database. Each verse comes formatted as [verse_number] text so the AI has clear verse boundaries.
The APB is the only version used. That fits with the experimental nature of the project, and I don't have to deal with royalty agreements.
3. Dynamic Prompt Building
The AI doesn't just get thrown a verse and told "analyze this." I built specialized prompt templates for each analytical perspective. The system dynamically constructs prompts with context-aware placeholders:
{reference}: Contains the full APB text{bible_version_instruction}: Tells the AI to use the provided biblical text from the Anselm Project Bible{json_instruction}: Enforces the structured output format{token_instruction}: Pushes for comprehensive analysis
The instruction reads: "using the provided biblical text (from the Anselm Project Bible)"
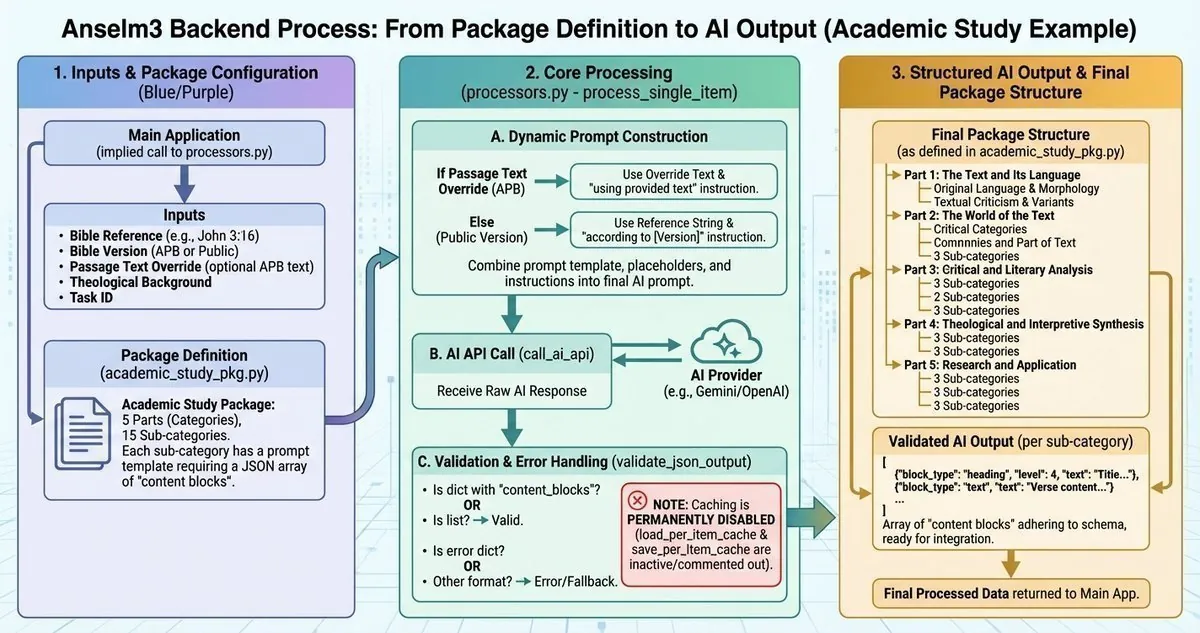
4. The Mixture-of-Experts Architecture
Here's where it gets interesting. A single Scholarly report isn't generated by one AI call - it's generated by fourteen separate AI calls, each acting as a specialized expert. This same mixture-of-experts architecture also powers the topical report engine.
The package structure defines five major parts:
Part 1: The Text and Its Language
- Original Language and Morphology expert
- Textual Criticism and Variants expert
Part 2: The World of the Text
- Historical and Archaeological Context expert
- Social-Scientific and Cultural Analysis expert
- Comparative Literature expert
Part 3: Critical and Literary Analysis
- Composition and Formation expert (Source, Form, Redaction Criticism)
- Narrative and Rhetorical Analysis expert
- Linguistic and Semantic Analysis expert
Part 4: Theological and Interpretive Synthesis
- History of Interpretation expert
- Doctrinal and Canonical Theology expert
- Current Debates and Peer Review expert
Part 5: Research and Application
- Methodological Frameworks expert
- Future Research and Thesis Development expert
- Scholarly Writing and Resources expert
Each expert receives the same biblical text but with a completely different prompt focused on their area of expertise. The morphology expert analyzes Greek/Hebrew grammar. The textual criticism expert examines manuscript variants. The rhetorical analysis expert identifies persuasive strategies. And so on.
The system processes these sequentially, validates each response, and assembles them into a cohesive report structure. This approach reduces hallucinations because each AI call has a narrow, well-defined task rather than trying to be an expert in everything at once.
5. Structured AI Output
Every report uses a universal content block system. The AI must return JSON in this format:
{
"module_name": "...",
"category_name": "...",
"sub_category_name": "...",
"package_name": "Scholarly",
"content_blocks": [
{"block_type": "heading", "content": "...", "level": 2, ...},
{"block_type": "text", "content": "...", ...},
{"block_type": "list", "items": [...], "ordered": true, ...}
]
}
This ensures consistent formatting across all report types while allowing flexible content structure. The AI can use headings, paragraphs, ordered lists, or unordered lists - whatever makes the most sense for the content.
6. Validation and Output
After the AI responds, the system validates the output against the schema. If the AI tried to cheat or return malformed data, it gets rejected. Only properly structured, valid responses make it through to become your report.
No Caching
I removed caching entirely from the system. Every report is generated fresh. This was intentional - I wanted to ensure the AI could incorporate any improvements or refinements I made to prompts without being locked into old cached responses.
The Result
The pipeline is straightforward but comprehensive. Validate the reference, fetch the text, build fourteen specialized expert prompts, call the AI fourteen times with different analytical perspectives, enforce structured output for each response, validate every response, and assemble them into a cohesive report.
This mixture-of-experts approach means a single Scholarly report represents fourteen different analytical perspectives, each focused on its own domain of biblical scholarship. The morphologist doesn't try to do textual criticism. The rhetorician doesn't try to do archaeology. Each expert stays in their lane.
It's the first engine I built, and honestly, I haven't needed to replace it because it works. The character study engine came later and uses a similar mixture-of-experts approach.
If you want to see what these reports actually look like, check out the Share Gallery. Anyone can view shared reports, even without an account. Or create your own biblical report to experience the fourteen-expert system firsthand.
God bless, everyone.
Related Articles
How Anselm's Topical Reports Produce Accurate Biblical Theology
Anselm's topical reports deliver accurate biblical theology: a mixture-of-experts that scans the can...
How the Anselm Project Builds AI-Powered Biblical Character Studies
Anselm Project builds AI-powered biblical character studies with a five-expert system, phased workfl...

Jerusalem Rejected the Gift
Matthew 2's shocking image of Kings and Priests rejecting God's gift: how worship continued while th...