How the Anselm Project Bible Was Made
How the Anselm Project Bible was made: inside the translation pipeline, the mixture model approach, pericope workflow, judge selection, and strict JSON.
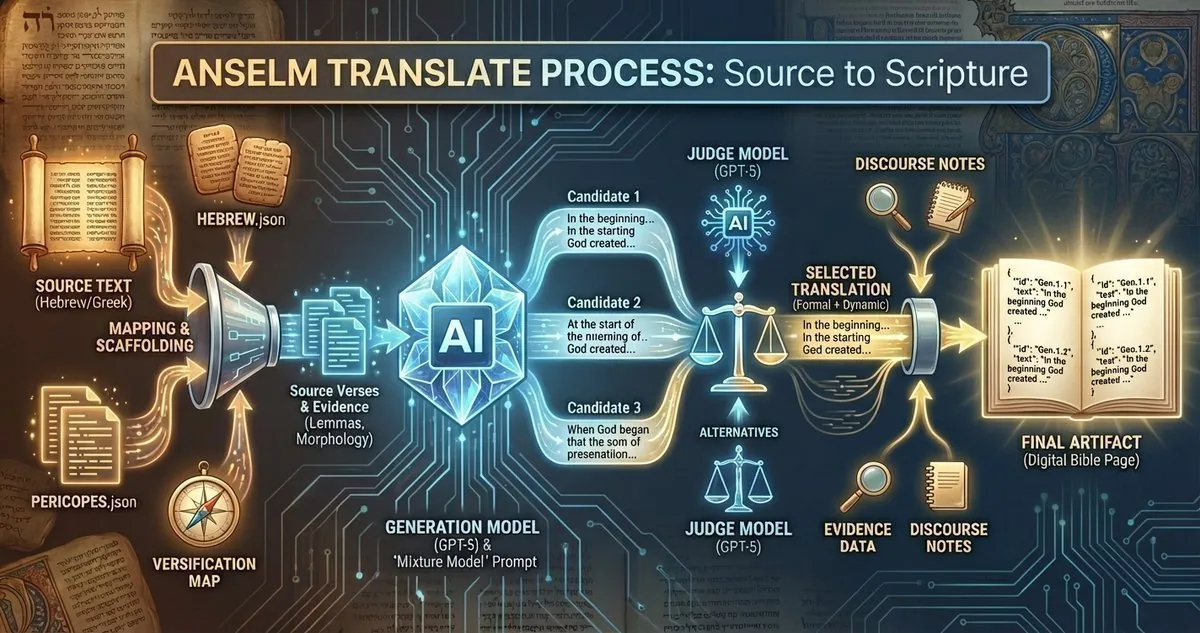
I've gotten questions about how the Anselm Project Bible actually got made. Here's the technical process behind version 1.
This describes the original translation pipeline. The current version as of this writing is 1.6, which includes significant upgrades I'll write about separately. But this is where it started.
The Mixture Model Philosophy
The translation engine operates on what I call a "mixture model" - it balances formal and dynamic equivalence. The instruction given to the AI is to be "literally accessible while maintaining dynamic ideological equivalency."
In practice, this means prioritizing transparency to the source text while rendering the underlying meaning when word-for-word would be obscure or misleading. The goal is contemporary English that sounds like the original but doesn't sacrifice accuracy for readability.
The tone instruction is explicit: dignified, literary, suitable for public reading. No casual idioms or slang. Timeless and authoritative.
Pericope-by-Pericope, Not Verse-by-Verse
The critical decision was translating complete pericopes rather than isolated verses. Verse-by-verse isolation loses literary context. The AI needs to understand the rhetorical flow, narrative structure, and thematic connections within each passage.
There are 2,022 pericopes across the entire Bible. Each one got processed as a complete unit. The AI received the full Hebrew or Greek text for the entire pericope at once, with clear verse boundaries marked.
This is why the APB presents Scripture in pericope form.
Multiple Candidates, Judge Selection
For each pericope, the system generates three translation candidates. Each candidate is a complete translation of the entire pericope by a different AI call using the same translation philosophy.
Then a separate judge AI evaluates all three candidates and selects the single best one based on adherence to the mixture model, cohesive voice across the pericope, faithful discourse markers, and stable dignified diction.
The generation model is GPT-5. The judge model is GPT-5-mini. The judge's only job is evaluation - it doesn't translate, it just picks the winner.
Style Continuity Through Context
Here's where it gets interesting. After completing each pericope, the system passes the previous translation as context to the next pericope. This ensures stylistic consistency across adjacent passages.
The AI doesn't just get thrown the next chunk of Hebrew or Greek in isolation. It sees what came before to maintain terminological and tonal coherence throughout the book.
Strict JSON Output
The AI must return translations in a strict JSON format:
{
"verses": [
{"id": "Gen.1.1", "text": "In the beginning God created the heavens and the earth."},
{"id": "Gen.1.2", "text": "Now the earth was formless and void..."}
]
}
No commentary. No markdown. No extra keys. Just the verse IDs and translated text. The system validates every response against this schema and rejects anything malformed.
This forces the AI to stay focused on translation rather than drifting into explanation or interpretation.
The Cheating Problem
Early versions had a serious issue - the AI was cheating. It recognized biblical patterns and defaulted to traditional translations instead of actually translating from the source text.
Mark 1:1 is the classic example. The Greek text provided to the system was "Αρχη του ευαγγελιου Ιησου χριστου" - but the system returned "The beginning of the gospel of Jesus Christ, the Son of God."
The problem? "The Son of God" isn't in the Greek text provided. The AI pulled from tradition instead of translating what it was given.
Version 1.5 fixed this with much more aggressive instructions: "You MUST NOT introduce nouns, verbs, clauses, titles, or concepts that are not present in the supplied source text." I also removed all references from the Bible in the translation prompt to try and force the model to translate more honestly.
In my instructions, I gave the Greek equivalent I came up with for "A quick brown fox jumped over the lazy brown dog," rather than biblical references. AI will cheat, I learned.
The system now also generates rationale notes from the AI explaining translation choices for ambiguous terms. This keeps things honest when the Greek or Hebrew is legitimately unclear.
Evidence Building
After translating each pericope, the system automatically builds four types of evidence:
Lemmas - Root word forms for every Greek and Hebrew term in the passage
Morphology - Grammatical parsing for each word (tense, voice, mood, case, number, gender)
These linguistic details power the biblical lexicon and enrich every passage report.
Parallels - Three to five cross-references to related passages
Text Critical Apparatus - A post-hoc analysis of manuscript variants and textual decisions
These run as separate automated processes after the translation completes. Each one uses the same source texts but with specialized prompts focused on linguistic analysis rather than translation.
Versification Mapping
Some pericopes required special handling because Hebrew and English versification systems don't align. The script includes a mapping table for passages where verse numbering differs between the Masoretic Text and standard English Bibles.
For example, Joel 2:28-32 in English is Joel 3:1-5 in Hebrew. The system handles this by looking up the correct Hebrew reference when fetching source text but outputting the English reference in the final translation.
The Token Cost
Final token count for the entire version 1 of the Anselm Project Bible: 253,151,552 tokens. That breaks down to 45,999,308 input tokens and 207,156,244 output tokens.
Every pericope generated three candidates, then the judge evaluated them. For 2,022 pericopes with three candidates each, that's 6,066 translation calls plus 2,022 judge calls plus thousands of evidence-building calls.
The system tracked token usage for every single pericope and stored it in separate JSON files for later analysis.
The Foundation
This pipeline generated version 1 of the Anselm Project Bible. The pericope-wide approach prevents context loss. The multi-candidate system with judge selection reduces reliance on any single AI generation. The strict output validation prevents drift.
The mixture model philosophy came from studying how translation committees actually work - they balance competing priorities and make judgment calls about when to prioritize form versus meaning. This same committee-style approach drives the biblical report generation system.
Version 1.6 introduced significant changes to address the cheating problem and other issues discovered through user feedback. That's a separate post. But this foundation - the pericope translation pipeline, the mixture model, the multi-candidate approach - remains the core of how the APB gets made.
The Anselm Project Bible is free and doesn't require an account. Check it out here.
God bless, everyone.
Related Articles
Anselm Project Bible v2.0 Released
Version 2.0 of the Anselm Project Bible introduces a blind-translator pipeline, Grok-powered generat...

Elon Musk and the Bible: Anselm Project v1.8
Anselm Project rebuilt its biblical translation engine (v1.8) with Grok 4.1: a four-step pipeline fo...
Genesis 3:15 Explained: Protoevangelium, Hebrew Grammar, and Messianic Seed
Explore Genesis 3:15 as the protoevangelium with grammatical, theological, and canonical readings th...